作者:涛之雨
其他分会场(内容完全一样,随手多发一处。。。)
cnblogs : https://www.cnblogs.com/taozhiyu/p/14493476.html
记一次有限制的网页pdf破解
起因
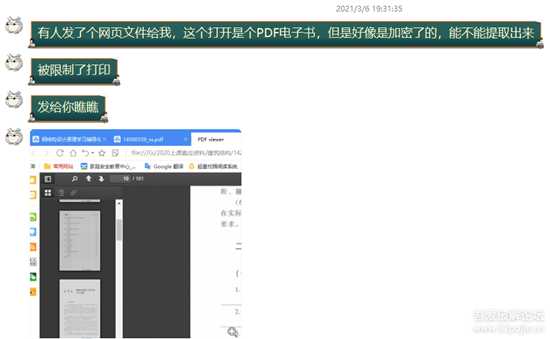
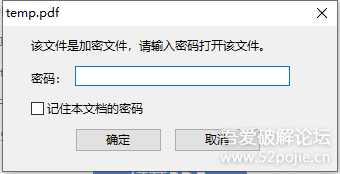
1.png
(文件附在文末)
初步分析
首先用chrome浏览器打开,查看效果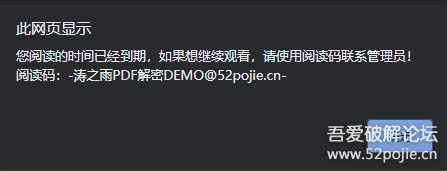
2.png
点击确定,F12打开控制台(我怎么打不开)
那就ctrl+shift+I打开控制台(打开了)
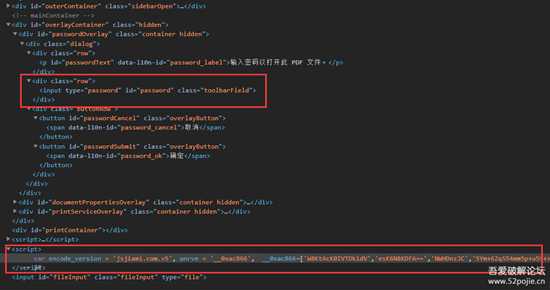
那肯定是js搞的鬼,随手翻一下js就看到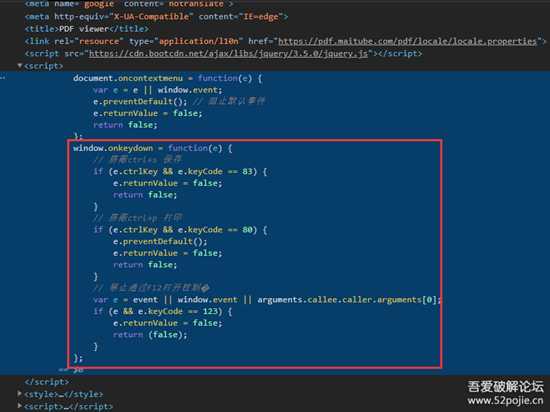
3.png
(有什么用。。。可以有不下于5种方法绕过)
列举一下一瞬间想到的(欢迎补充)
- 最简单的就是本地
js啊!直接打开编辑。。。- 上述的
ctrl+shift+I- 菜单$\to$更多工具$\to$开发者工具
ctrl+shift+C(这是快速打开UI布局分析工具,就是这个小按钮)4.png
fd自动转发(针对服务器返回的数据,保存到本地然后转发)- 先打开控制台,再打开网页(斜眼笑)

大胆猜测一下,一个HTML30多M,说明数据都在本地,这个弹窗应该是服务器验证之类的
所以内容所占最多的部分就是PDF文件的主体。
使用010 Editor打开网页(因为我电脑问题。。。sublime打开直接就卡死了。。。汗-_-||),
向下随便翻翻,就找到一大堆的内容(如下图所示)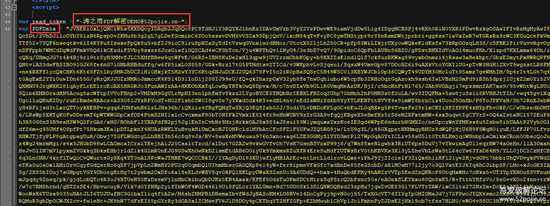
5.png
大致可以猜测为base64。
当然有没有加密啥的都不知道,只知道最后一步应该是base64。
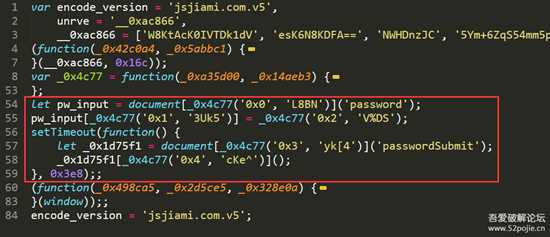
然后向下看,有好几个script标签。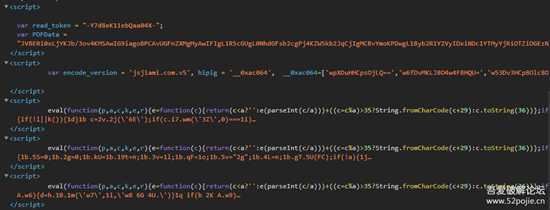
6.png
不得不说,这个作者还是挺有心的,下面三个
eval的加密,上面一个号称耶稣也还原不了的加密。唔,先不解密吧,(肯定这块就有猫腻了)
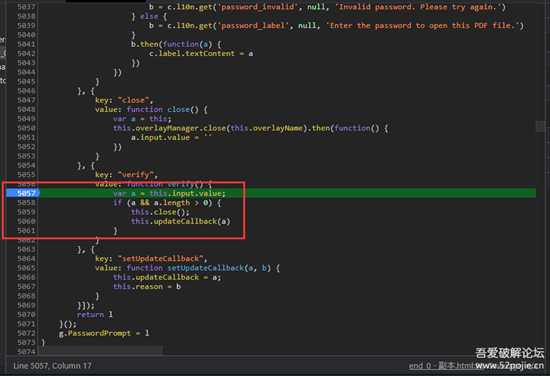
刷新一下页面,在弹窗的时候按下暂停键,(注:在source标签里)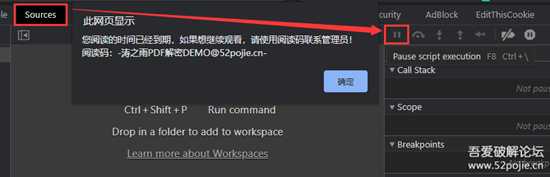
7.png
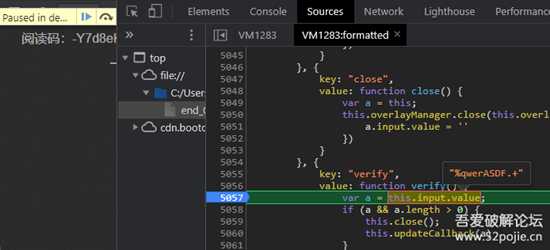
点确定后就断下来了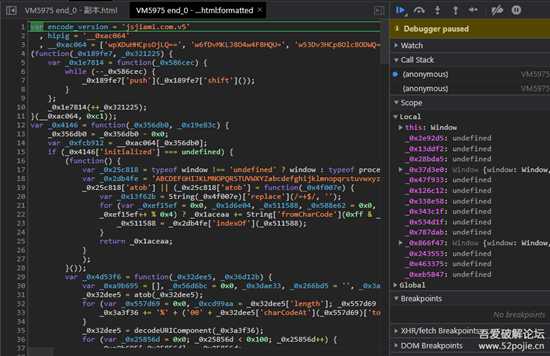
8.png
稍作格式化,有alert出现
9.png
向上翻一下,找到else所在判断的另一个分支。。。这灵魂判断。。。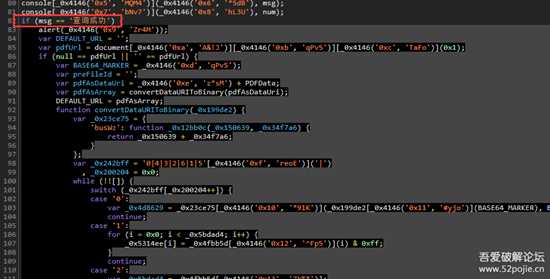
10.png
不管38妇女节(虽然还没到)
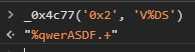
复制粘贴直接运行。(有点慢。。。)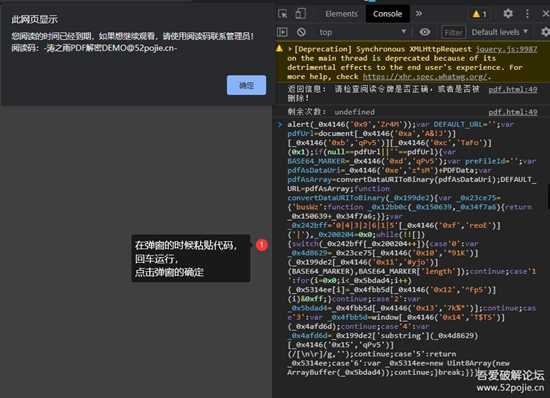
11.png
这不就运行出来了么: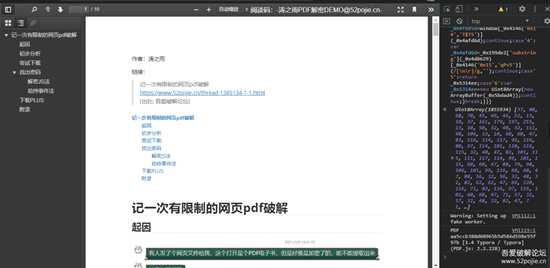
11_plus.png
好了这就是主要的代码了,拿出来解密再重命名一下就是:
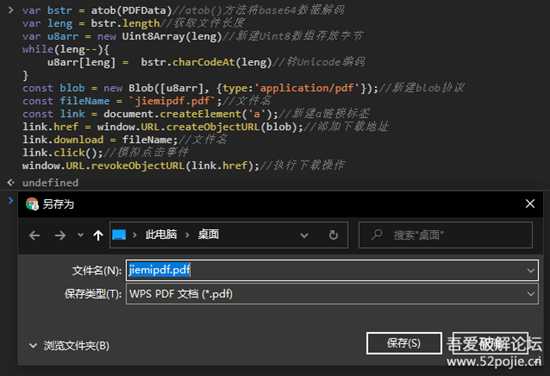
var DEFAULT_URL = '';var pdfUrl = document.location.search.substring(1);if (null == pdfUrl || '' == pdfUrl) { var BASE64_MARKER = ";base64,"; var preFileId = ''; var pdfAsDataUri = "data:application/pdf;base64," + PDFData; var pdfAsArray = convertDataURIToBinary(pdfAsDataUri); DEFAULT_URL = pdfAsArray; function convertDataURIToBinary(data) { var point = data.indexOf(BASE64_MARKER) + BASE64_MARKER.length; var b64 = data.substring(point).replace(/[\n\r]/g, ''); var raw = window.atob(b64); var rawlength = raw.length; var U8array = new Uint8Array(new ArrayBuffer(rawlength)); for (i = 0; i < rawlength; i++) { U8array[i] = raw.charCodeAt(i) & 255; } return U8array; }}明显的的看到了,协议是application/pdf,编码是base64。
尝试下载
base64解码后直接保存16进制不就好了,随手写了python解密保存
温馨提示,文件有点大,我是直接用
010 Editor把前后都删掉,然后添加前后部分的
import base64PDFData = "JVBERi0xLjYKJb/3***********这里是完整的base64,30多m,直接base64后放出来估计要被h大打死(暴筋)**********8mCjMyMzIxMjkwCiUlRU9GCg=="with open('temp.pdf', 'wb') as f: f.write(base64.b64decode(PDFData))